
Zero Trust vs. SASE: Everything You Need to Know
Zero Trust vs. SASE: Everything You Need to Know Introduction As the cyber world continues to change, companies need to look beyond conventional security
Zero Trust vs. SASE: Everything You Need to Know Introduction As the cyber world continues to change, companies need to look beyond conventional security

Cloud Security Posture Management (CSPM) Introduction In the era of digital transformation, organizations are moving to the cloud at an unprecedented pace. While the

How to Strengthen Security Using CIS Controls and Posture Analysis Introduction In the fast-paced and ever-evolving world of cybersecurity, defending digital infrastructure goes far
Table of Contents
Most data scientists are not expert programmers. While they are adept at choosing or creating the best model to solve a machine learning problem, they don’t necessarily have the expertise to package, test, deploy, and maintain this model in a production environment. That’s exactly where MLOps comes to the rescue.
MLOps creates a bridge between data scientists and production teams. It is a practice that combines DevOps with Machine Learning. This article talks about MLOps, why it is needed, the challenges of MLOps, the tools available, and how MLOps pipelines work.
Dive deeper into the world of cloud technology and IT mastery with IPSpecialist! Get the best course by accessing comprehensive DevOps certification training and resources. From beginner-level DevOps courses to mastering Microsoft, AWS, Cisco, and more, IPSpecialist offers diverse courses, study guides, and practice exams tailored to amplify your skills. Elevate your career in the dynamic realm of DevOps—explore their offerings now!
Machine Learning Operations (also known as MLOps) is a collection of tools and best practices for improving communication across teams and automating the end-to-end machine learning life cycle to improve continuous integration and deployment efficiency. It is a concept that refers to the merger of long-established DevOps methods with the growing science of Machine Learning.
MLOps encompasses more than model construction and design. It includes data management, automated model development, code generation, model training and retraining, continuous model development, deployment, and model monitoring. Incorporating DevOps ideas into machine learning offers a shorter development cycle, improved quality control, and the ability to adapt to changing business needs.
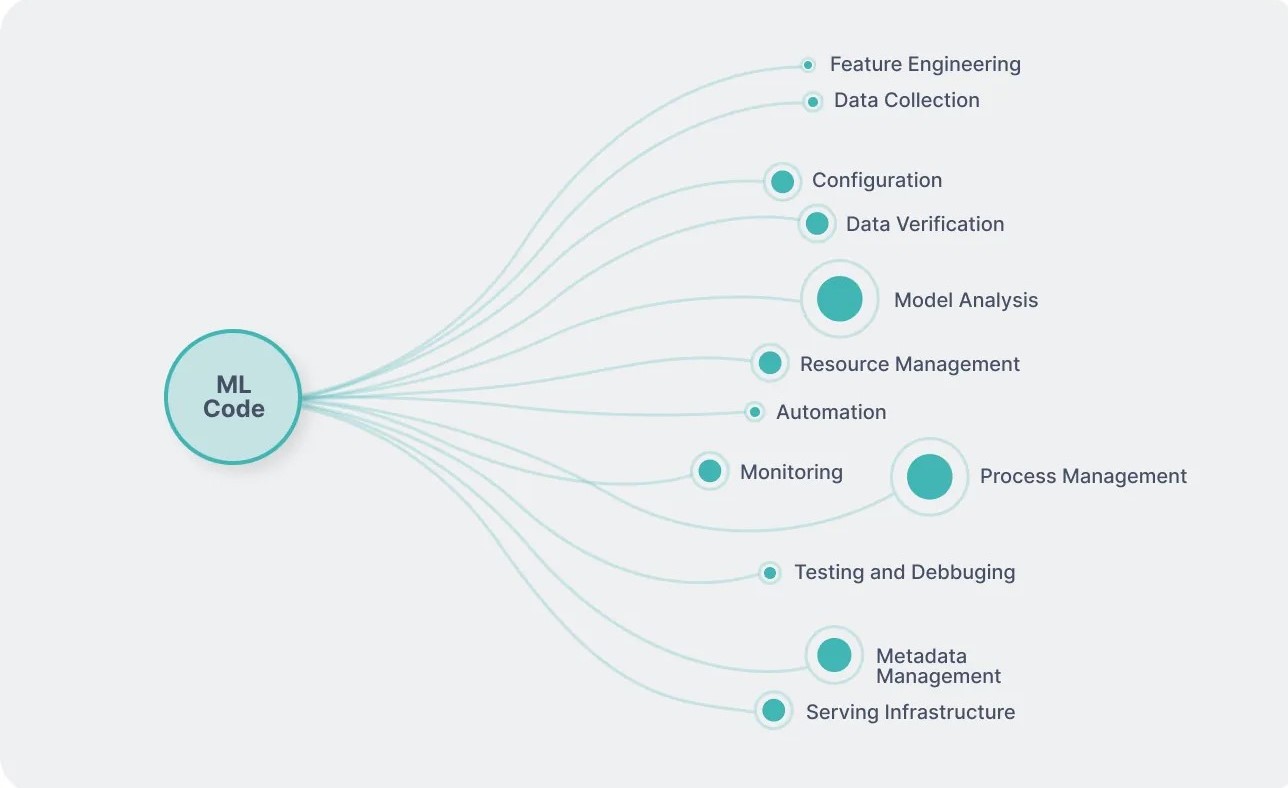
DevOps and MLOps are both methodologies aimed at improving the software development and deployment process but differ in focus and objectives. Here’s a comparison of DevOps and MLOps:
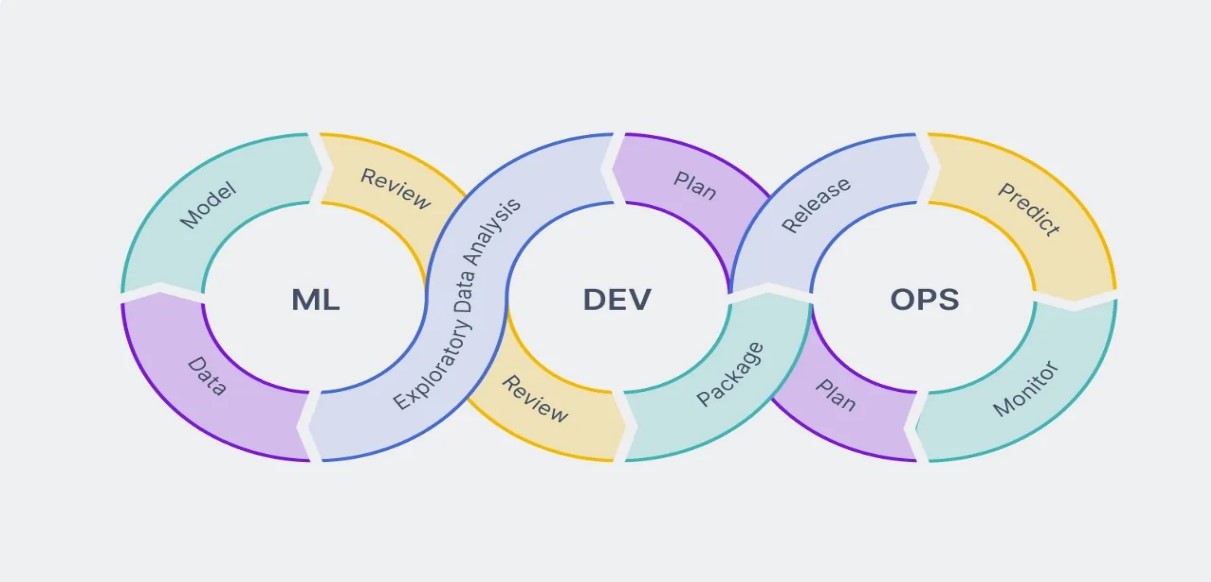
To understand MLOPs better, it helps to emphasize the core differences between MLOps and DevOps.
DevOps teams are populated mainly by software engineers and system administrators. In contrast, MLOps teams are more diverse—they must include:
Scoping entails the preparation for the project. Before starting, you must decide if a given problem requires a machine learning solution—and if it does, what kind of machine learning models are suitable. Are datasets available or need to be gathered? Are they representative of reality or biased? What tradeoffs need to be respected (e.g., precision vs. inference speed)? Which deployment method fits the best? A machine learning operations team needs to address these issues and plan a project’s roadmap accordingly.
Being able to reproduce models, results, and even bugs is essential in any software development project. Using code versioning tools is a must.
However, in machine learning and data science, versioning of datasets and models is also essential. You must ensure your datasets and models are tied to specific code versions.
Open source data versioning tools such as DVC or MLOps platforms are crucial to any machine learning operations pipeline. In contrast, DevOps pipelines rarely need to deal with data or models.
The MLOps community adopted all the basic principles of the unit and integration testing from DevOps.
However, the MLOps pipeline must also include tests for both model and data validation. Ensuring the training and serving data are in the correct state to be processed is essential. Moreover, model tests guarantee that deployed models meet the expected criteria for success.
Deploying offline-trained models as a prediction service is rarely suitable for most ML products. Multi-step ML pipelines responsible for retraining and deployment must be deployed instead. This complexity requires the automation of previously manual tasks performed by data scientists.
Model evaluation needs to be a continuous process. Not unlike food and other products, machine learning models have expiration dates. Seasonality and data drifts can degrade the performance of a live model. Ensuring production models are up-to-date and on par with the anticipated performance is crucial.
Implementing MLOps benefits your organization’s machine learning system in the following ways:
Since the field is relatively young and best practices are still being developed, organizations face many challenges in implementing MLOps. Let’s go through three main challenge verticals.
The current state of ML culture is model-driven. The research revolves around devising intricate models and topping benchmark datasets, while education focuses on mathematics and model training. However, the ML community should devote some of its attention to training on up-to-date open-source production technologies.
Adopting a product-oriented culture in industrial ML is still an ongoing process that meets resistance, which might make it more difficult to adopt it into an organization seamlessly.
Moreover, the multi-disciplinary nature of MLOps teams creates friction. Highly specialized terminology across different IT fields and differing levels of knowledge make communication inside hybrid teams difficult. Additionally, forming hybrid teams of data scientists, MLEs, DevOps, and SWEs is costly and time-consuming.
Most machine learning models are served on the cloud with requests by users. Demand may be high during certain periods and fall back drastically during others.
Dealing with a fluctuating demand in the most cost-efficient way is an ongoing challenge. Architecture and system designers also have to deal with developing infrastructure solutions that offer flexibility and the potential for fast scaling.
Machine learning operations lifecycles generate many artifacts, metadata, and logs. Managing all these artifacts with efficiency and structure is a difficult task.
The reproducibility of operations is still an ongoing challenge. Better practices and tools are being continuously invented.
MLOps, which stands for Machine Learning Operations, is all about streamlining the process of developing, deploying, and maintaining machine learning models. There are different levels of MLOps maturity, indicating how automated and efficient your ML lifecycle is. Here’s a breakdown of some common MLOps levels:
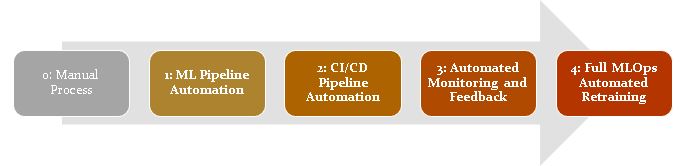
This is the starting point, where everything is done manually. Data scientists handle data preparation, model training, and deployment, often using tools like Jupyter Notebooks. It’s slow, error-prone, and difficult to reproduce results.
Here, data scientists focus on automating the ML pipeline itself. They use tools to automate data processing, model training, and evaluation. This improves efficiency and reduces errors, but deployment is still manual.
This level integrates MLOps with CI/CD (Continuous Integration/Continuous Delivery) practices. Changes in code trigger automatic testing, training, and deployment. This ensures consistent and reliable deployments.
At this level, models are continuously monitored in production. Metrics are collected to track performance and detect drift. Alerts are generated if issues arise, and retraining pipelines can be automated based on these.
This is the most advanced level, where the entire ML lifecycle is automated. Monitoring and feedback are automated, and models are automatically retrained based on new data or performance degradation.
Let’s go through a few of the MLOPs best practices, sorted by the stages of the pipeline.
MLOps offers a structured approach to developing, deploying, and monitoring machine learning models. By incorporating DevOps principles, MLOps aims to bridge the gap between data science and production teams, ultimately leading to more efficient and reliable machine learning systems.
While DevOps focuses on software systems as a whole, MLOps places particular emphasis on machine learning models, requiring specialized treatment due to the data and models involved. MLOps teams are also more diverse, encompassing data scientists, software engineers, and business development specialists. Additionally, MLOps incorporates data versioning, model testing, and continuous monitoring, aspects not typically required in traditional DevOps pipelines.
Machine learning models can degrade over time due to factors like data drift and seasonality. Monitoring helps ensure models are performing as expected and enables proactive retraining when necessary.
MLOps faces challenges on multiple fronts. Organizationally, fostering a product-oriented culture and bridging the communication gap between different disciplines can be difficult. Architecturally, designing systems to handle fluctuating demand requires careful consideration. Operationally, managing artifacts, metadata, and logs efficiently and ensuring reproducibility of operations are ongoing areas of focus.



